Speeding Up LLM Inference
Large Language Model inference optimization techniques
The development of LLMs and the infrastructure around them is evolving at an unthinkable rate. Every week, new approaches emerge to speed up or compress models.

In this blog post, I will try to summarize the most relevant techniques to speed up inference of LLMs to increase token generation speed and reduce memory consumption.
1. Using 16-bit precision and mixed-precision
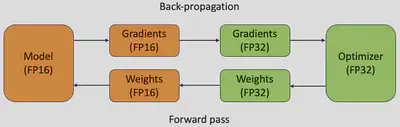
When training complex deep neural networks on a GPU, we often don’t use the highest possible accuracy. We use 32-bit calculations in PyTorch by default. If we want our model to work faster, we can use lower accuracy, like 16-bit calculations. Here’s how this helps:
- Saves Memory: Using 32-bit calculations takes up twice as much space on the GPU as 16-bit ones. So by using 16-bit, we make better use of the available memory.
- Increases Speed: GPU can work on lower accuracy calculations more quickly.
There’s also something called mixed-precision training. This is a key method to make things work even faster on modern GPUs. In this approach, we don’t just use 16-bit calculations all the time. Instead, we switch between 32-bit and 16-bit during the training process, which is why it’s called “mixed” precision. This way, we can significantly speed up the training.
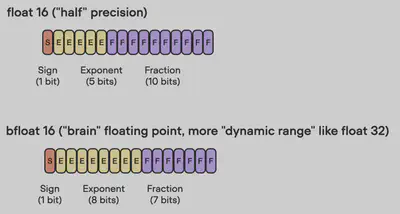
2. Brain floating point
Bfloat16 is a floating-point number format proposed by Google. Google developed this format for machine learning and deep learning applications, particularly in their Tensor Processing Units (TPUs). While bfloat16 was originally developed for TPUs, this format is now supported by several NVIDIA GPUs.
3. Quantization (模型量化)
To further increase model performance during inference, quantization can be used. This technique converts model weights from floating-point numbers to low-bit integer representations, such as 8-bit or even 4-bit integers.
There are two methods:
- Post-Training Quantization (PTQ): The model is trained, then its weights are converted to lower precision without more training, which is relatively inexpensive.
- Quantization-Aware Training (QAT): Applied during pre-training or fine-tuning, QAT can perform better but requires more resources and access to specific training data.
Post-Training Quantization will be used to speed up an existing model on inference. Quantization-Aware Training will be used to train a new model from scratch.
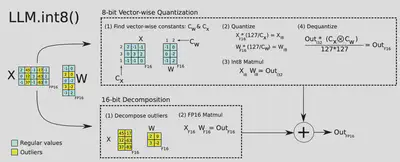
We should be aware of the gap between theoretical optimal quantization strategy and the hardware kernel support. Due to the lack of GPU kernel support for certain types of matrix multiplication (e.g. INT4 x FP16), not all the methods result in speedup for the actual inference.
What’s Quantization?
Quantization, in the context of deep learning, refers to the process of constraining an input from a continuous or large set to output in a discrete (finite) range. Essentially, it’s the mapping of a large set of input values to output values in a smaller set, often in the process of reducing the numerical precision.
In neural networks, quantization helps in reducing the model size and computation requirements. By using lower precision (like 8-bit instead of 32-bit floats), less memory is required to store the weights, and computations can be done more quickly. This makes the model faster and more efficient, particularly beneficial for deployment on resource-constrained devices like mobile phones.
4. Fine-Tuning With Adapters
Fine-tuning doesn’t directly make the final model work faster, but there are some strategies to help it perform better:
Quantization: First, train your model on the specific problem you’re trying to solve. Then, use a process called quantization to simplify it. This might reduce the model’s quality a little, but the initial training on the specific problem can balance that out.
Small Adapters: Another way is to add small adapters for different tasks. These are little extra layers added to the existing model that are trained by themselves. Since these adapter layers are simple, they let the model learn and adapt quickly.
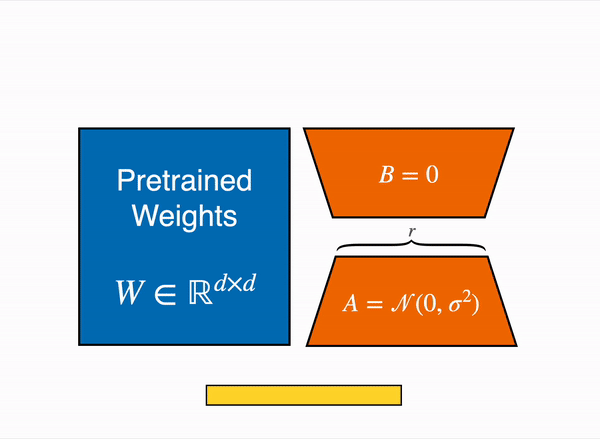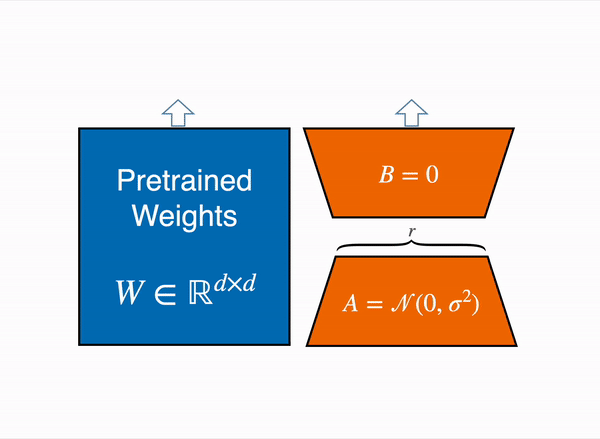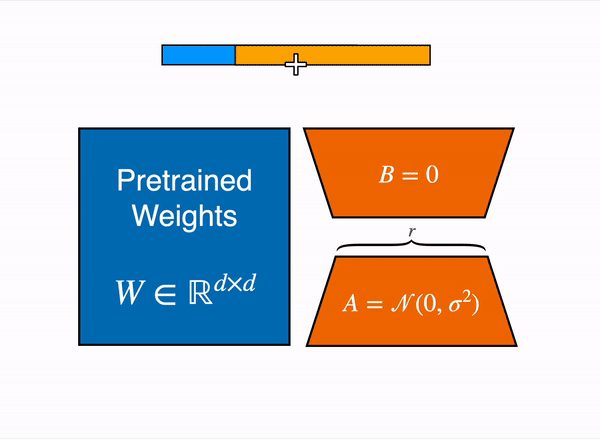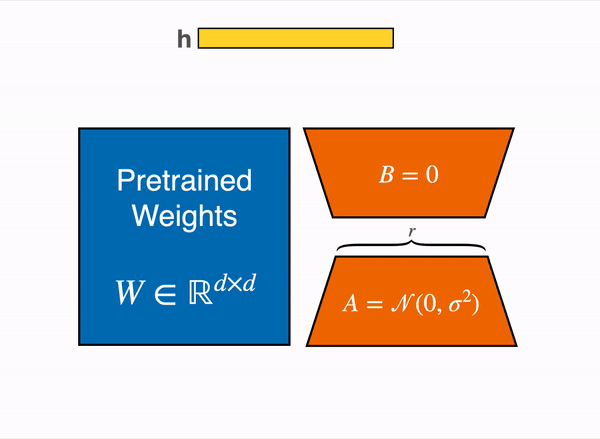
QLoRA paper, a new way of democratizing quantized large transformer models: In few words, QLoRA reduces the memory usage of LLM finetuning without performance tradeoffs compared to standard 16-bit model finetuning. This method enables 33B model finetuning on a single 24GB GPU and 65B model finetuning on a single 46GB GPU.
More specifically, QLoRA uses 4-bit quantization to compress a pretrained language model. The LM parameters are then frozen and a relatively small number of trainable parameters are added to the model in the form of Low-Rank Adapters. During finetuning, QLoRA backpropagates gradients through the frozen 4-bit quantized pretrained language model into the Low-Rank Adapters. The LoRA layers are the only parameters being updated during training.
See https://huggingface.co/blog/4bit-transformers-bitsandbytes
5. Continuous Batching
Graphics Processing Units (GPUs), known for their ability to handle many calculations at once, offer impressive parallel computing speeds. GPUs like the A100 can perform trillions of calculations per second, and others like the H100 can even do more. However, when working with Large Language Models (LLMs), GPUs often can’t use their full potential because too much of the chip’s memory is taken up by loading model parameters.
One effective approach to mitigate this limitation is through batching. Instead of loading new model parameters for every input sequence, batching allows for loading the parameters once and utilizing them to process multiple input sequences. This optimization strategy efficiently utilizes the chip’s memory bandwidth, resulting in higher compute utilization, improved throughput, and more cost-effective LLM inference. By employing batching techniques, the overall performance of LLMs can be significantly enhanced.
One recent such proposed optimization is continuous batching. Instead of waiting until every sequence in a batch has completed generation, Orca implements iteration-level scheduling, where the batch size is determined per iteration. The result is that once a sequence in a batch has completed generation, a new sequence can be inserted in its place, yielding higher GPU utilization than static batching.
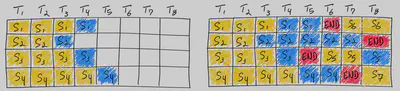
See Anyscale’s blog post for a more detailed review and benchmarks on continuous batching: https://www.anyscale.com/blog/continuous-batching-llm-inference
Conclusion
In this blog post, we’ve covered some of the most relevant techniques to speed up inference of LLMs to increase token generation speed and reduce memory consumption. We’ve seen how to use 16-bit precision and mixed-precision, Brain floating point, quantization, fine-tuning with adapters, and continuous batching.
The development of LLMs and the infrastructure around them is evolving at an unthinkable rate. But it is still in infancy. There are many more techniques to be discovered and implemented. I’m sure we’ll see many more exciting developments in the near future.
Hongchao Deng (邓洪超)
Entrepreneur, Technologist
My research interests include programming, artificial intelligence, Kubernetes and infrastructure matter.